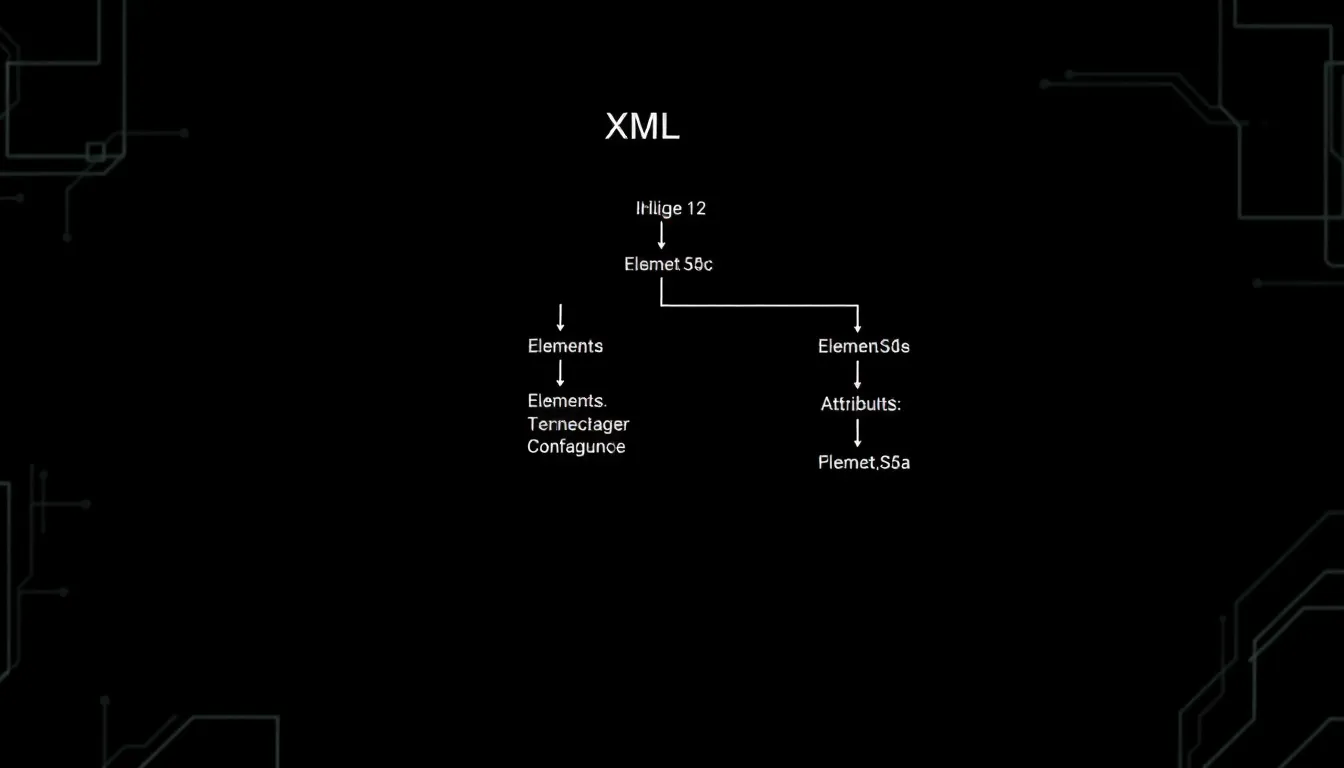
XML, or Extensible Markup Language, is a versatile format for data representation this is both human-readable and machine-readable. At its core, XML is structured as a tree of nodes, where each node can be an element, an attribute, or text content. Understanding the nuances of XML structure very important for effective data manipulation.
Elements are defined by opening and closing tags, which can contain attributes that provide additional context. For instance:
<book title="Effective C++">
<author>Scott Meyers</author>
<year>2005</year>
</book>
In this example, the title that describes this book. The nested elements
One of the key aspects of XML is that it’s inherently hierarchical. This means that data can be nested at multiple levels, allowing for complex structures. For example:
<library>
<book title="Effective C++">
<author>Scott Meyers</author>
<year>2005</year>
</book>
<book title="Design Patterns">
<author>Gamma, Helm, Johnson, Vlissides</author>
<year>1994</year>
</book>
</library>
This structure allows you to group related data logically, which can be crucial when parsing or transforming XML documents. It is also worth noting that XML is case-sensitive, which means that
Whitespace in XML is generally ignored, making it flexible for formatting. However, excessive whitespace can make documents unnecessarily large and less readable. When designing XML structures, aim for clarity while maintaining efficiency.
XML also supports namespaces, which help to avoid element name conflicts, especially in documents that integrate multiple XML schemas. A namespace is declared using the xmlns attribute, allowing you to differentiate elements from different vocabularies:
<book xmlns:fiction="http://example.com/fiction">
<fiction:title>The Great Gatsby</fiction:title>
<fiction:author>F. Scott Fitzgerald</fiction:author>
</book>
Namespaces can be particularly beneficial when dealing with XML documents that combine data from various sources, ensuring that element names do not clash.
Implementing efficient conversion techniques
When it comes to converting XML data to other formats, efficiency is key. One common approach is to leverage libraries that streamline the parsing and transformation processes. Python, for instance, offers several libraries such as xml.etree.ElementTree, lxml, and xmltodict that can simplify this task significantly.
Using xml.etree.ElementTree, you can parse XML and access its elements easily. Here’s a basic example of how to read an XML file and extract data:
import xml.etree.ElementTree as ET
# Load and parse the XML file
tree = ET.parse('library.xml')
root = tree.getroot()
# Iterate through each book element
for book in root.findall('book'):
title = book.get('title')
author = book.find('author').text
year = book.find('year').text
print(f'Title: {title}, Author: {author}, Year: {year}')
This code snippet demonstrates how to load an XML file, parse it, and retrieve specific data. The findall method is particularly useful for locating elements by tag name, while get and find allow you to access attributes and nested elements, respectively.
If you need to convert XML to a dictionary format for easier manipulation, xmltodict is an excellent choice. Here’s how you can use it:
import xmltodict
# Load the XML file and convert it to a dictionary
with open('library.xml') as xml_file:
data_dict = xmltodict.parse(xml_file.read())
# Accessing the data
for book in data_dict['library']['book']:
print(f"Title: {book['@title']}, Author: {book['author']}, Year: {book['year']}")
This method allows you to work with the XML data as a native Python dictionary, making it much easier to manipulate and integrate with other data processing tasks.
For more complex transformations, you might consider using XSLT (Extensible Stylesheet Language Transformations). XSLT allows you to define rules for transforming XML documents into different formats, including HTML or plain text. Here’s a simple XSLT example that transforms a library XML into an HTML table:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/library">
<html>
<body>
<table border="1">
<tr><th>Title</th><th>Author</th><th>Year</th></tr>
<xsl:for-each select="book">
<tr>
<td><xsl:value-of select="@title"/></td>
<td><xsl:value-of select="author"/></td>
<td><xsl:value-of select="year"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
In this example, the XSLT stylesheet matches the root library element and generates an HTML table with rows for each book. The <xsl:for-each> construct allows you to iterate over each book element, extracting the title, author, and year.